Apr 22, 2026 · AI
Building a Framework That Actually Moves Orgs
Most transformation frameworks describe the destination. The useful ones move you, guide you, and measure the shift. A walk through the discipline of building a calibrated internal framework — comparative assessment, council validation, the 'why this approach' page, and why movement has to come before alignment, alignment before benchmarking.
The thing nobody tells you about transformation frameworks
Most transformation frameworks I've seen — including the well-respected ones — describe a destination. They tell you what mature looks like. They give you a five-level ladder. They map dimensions, cite sources, look credible.
What they mostly don't do is move the org.
I've been building one of these for a small group of small businesses going through an AI transformation. The most surprising thing about the work has been how much of the difficulty isn't in the content — it's in the discipline of building something productive. Something that, when a team reads it, actually changes a thing the next day.
This post is about that discipline. Not about the framework. This one is about the act of building.
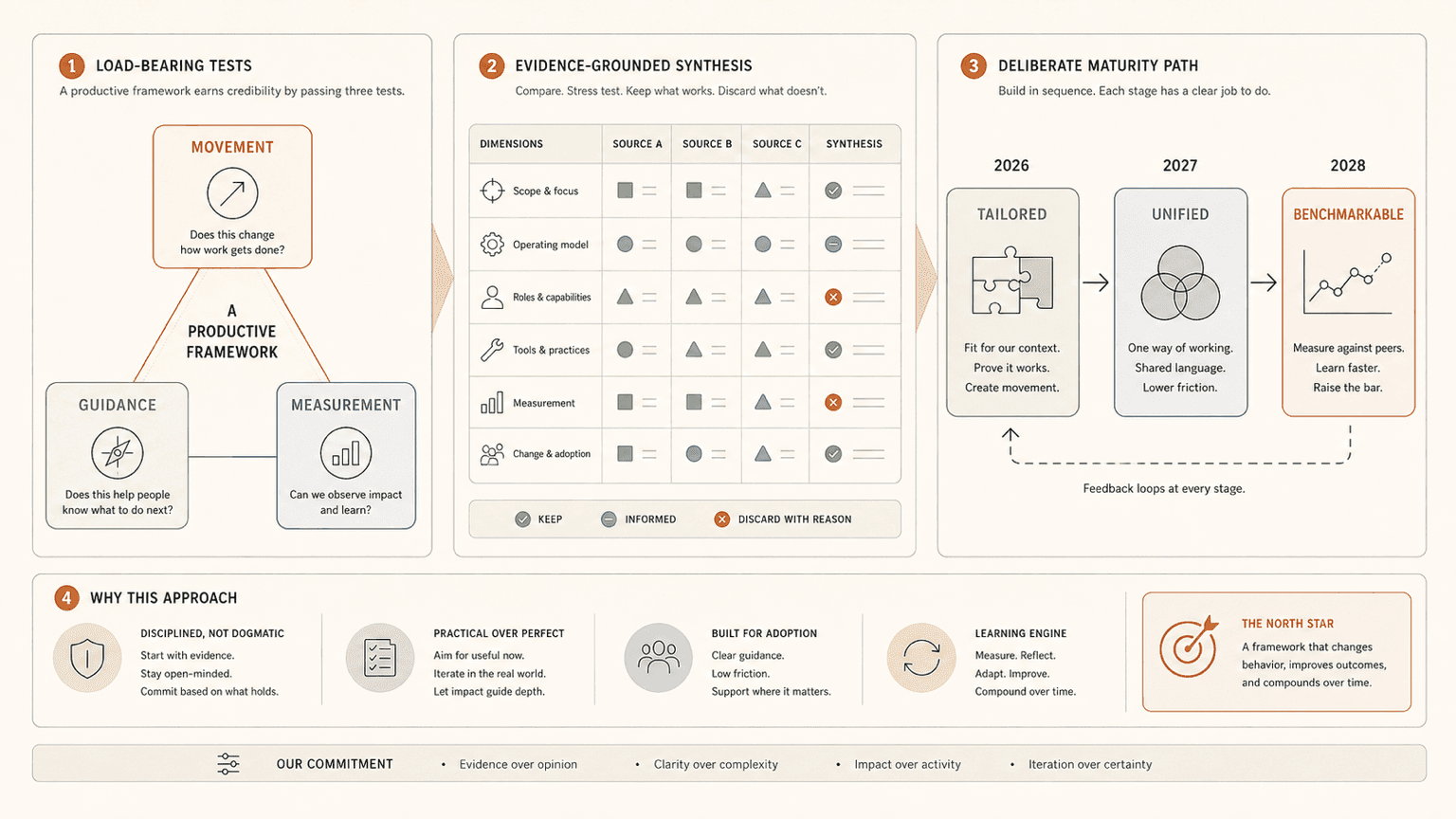
The three tests a productive framework has to pass
Let me start with the bar. A framework is productive if it does three things:
- Movement. It causes behaviour to change. Someone reads it and does something different on Monday.
- Guidance. It tells the reader what to do next, at the altitude they're at. Not what to aspire to. What to do.
- Measurement. It exposes whether the shift is happening. Not vibes. Signals.
Most published frameworks fail at least one of these. Plenty fail two. A descriptive ladder with no guidance fails Movement and Guidance both — it sits there, nicely structured, while nothing changes. A guidance-rich framework with no measurement fails Measurement, and you find out three quarters in that nobody's actually progressed.
The trick is the three tests aren't independent. A framework that moves people because it guides them and lets them measure their own progression is much harder to build than one that does any single test alone. The combination is the bar.
Generic universal models lose to calibrated ones
Here's the counter-instinct I keep running into: people building frameworks reach for the most universal model they can find. Big-4 model. Industry standard. ISO-style. The reasoning is "if I pick the broadest one, I can defend it to anyone."
The problem is the only metric that matters is things changing. A framework calibrated to a specific org's constraints — its scale, its culture, its regulatory context, its current capability floor — will move that org faster than a generic universal model. Every time.
This isn't a critique of the universal models. They're good at what they do: benchmarking across thousands of orgs, providing a common reference point, supplying defensible ladders. That's just not the job of an internal transformation framework. An internal framework's job is to move one org. For that, calibration beats universality.
Calibration doesn't mean abandoning the universal models. It means using them as evidence base — what's stable, what's contested, what's emerging — and then making deliberate, documented trade-offs against them.
Evidence-grounded synthesis, not best-of-class theatre
There's a thing I'll call best-of-class theatre that a lot of internal frameworks fall into. It looks rigorous from the outside. The framework "draws on" NIST, ISO, Microsoft, BCG, Deloitte, MIT CISR, McKinsey. Citation list. Maybe a logo wall.
Under the surface, the synthesis is rarely doing real work. The author has read the abstracts, picked up the labels, and built something that resembles the references without committing to a position on any of them. It's pastiche.
A productive synthesis is the opposite of that. For each contributing source you can answer:
- What we kept. A specific construct, level, or dimension we adopted.
- What we discarded. A specific construct we deliberately didn't adopt, with a reason.
- Why this call. Documented in the framework itself, not in someone's head.
In our case, the comparative assessment ran across NIST AI RMF, ISO/IEC 42001, Microsoft RAI Maturity Model, BCG, Deloitte, MIT CISR, McKinsey, UNESCO, Gartner, and SEI/Accenture, among others. ISO 42001 became the spine of the governance dimension because it's certifiable and EU AI Act adjacent. NIST stayed in scope as a complementary reference for governance framing. UNESCO's Acquire → Deepen → Create scale informed the workforce fluency dimension but didn't drive its level naming, because its teaching-oriented framing didn't map cleanly to the work-context behaviours we needed to assess. Gartner's 5-level ladder was not adopted as the spine, despite being the most widely cited framework in the space, because its rigid stage definitions assume a coordinated central transformation that doesn't fit a federation of autonomous BUs.
Each of those calls is documented. Each has a rationale. Each survives — or doesn't — when a senior person asks "why this?".
The discipline is brutal in practice. It's much faster to gesture vaguely at the references and call it done. The slow path — making a call on each, defending each call — is the difference between something that holds up under scrutiny and something that collapses the second a sceptical reader pokes at it.
The dual-model council as real validation
This is where I see most internal framework work go wrong.
If you ask one good AI to "synthesise these ten frameworks and tell me what to keep," you get a confident, well-written, and subtly miscalibrated answer. The model favours the labels it's seen most often in training. It smooths over genuine disagreements between sources. It plausibly hallucinates a source or two. And the output reads so cleanly you don't notice.
A multi-model council — independent passes from genuinely different model lineages — surfaces the gaps. Not because each model is more right than the others, but because where they converge you have stronger signal, and where they diverge you've found something worth investigating.
In our build, the council pattern caught:
- A dimension two of three models identified as missing from the existing scaffolding — the bridge between individual fluency and org maturity, which no published framework actually does cleanly.
- A level-naming inconsistency across internal references that a single-model pass had smoothed over silently.
- Three plausible-sounding "improvements" that all three models initially endorsed but which failed the council's own stress test on a second pass — they added the appearance of rigour, not rigour itself. We dropped them. Epistemic theatre in a tidy package.
The council pattern isn't decoration. It's the validation layer that catches gaps a single confident pass would let through. The moment you trust a single AI's "synthesis of industry frameworks" without it, you've outsourced your judgement to whatever the median of training data favoured. That's worse than just picking one framework and committing to it.
The "why this approach" discipline
This one's small but it's the difference between a framework that holds and a framework that crumbles.
Every design decision needs a documented rationale. Not in someone's head. Not in the Slack thread where it was discussed. In the framework.
The test is what I think of as the senior-person poke. A senior leader from outside the team reads the framework and asks, "Why this approach? Why not the off-the-shelf model from $LARGE_CONSULTANCY? Why these four dimensions? Why this sequencing?"
If the answer is "because we thought about it carefully," the framework dies in that conversation. If the answer is a documented page that lays out the structural context, the trade-offs, the alternatives that were considered, and the conditions under which the choice would change — the framework survives.
We made that page explicit in our build. It maps five named trade-offs (breadth vs actionability, benchmarking vs diagnostic precision, mandate vs advisory, structural purity vs readiness, completeness vs pace) to the alternatives considered, and gives a 2026 → 2027 → 2028 maturation path for when the trade-offs change. It pre-empts the most likely challenges from peer business groups with direct answers.
The "why this approach" page is not optional. A framework without that layer is a Wikipedia article — informative, ungrounded, unable to defend itself.
Designing for understanding under rapid change
The tech underneath this kind of framework moves fast — models, capabilities, regulation, market practice, all shifting on a quarterly cadence. The temptation is to keep updating the framework to chase the frontier.
That's a trap. A framework updated every quarter is one nobody learns. Staff can't internalise something that keeps shifting. BU leaders can't make annual planning decisions against a moving spec.
What worked for us was separating structure from specifics. The structure — the dimensions, the levels within each, the relationship between them — was designed to be stable for at least the 2026 horizon. The specifics underneath each level — example tools, assessment evidence, recommended practices — were treated as living content that updates with the tech.
Stability comes from structure, not specifics. Sounds obvious. It's the design discipline most internal frameworks fail at — they put specifics into the structure layer ("Level 3 means using GPT-5 for X") and the whole thing is obsolete in six months.
Movement before alignment, alignment before benchmarking
This is the sequencing call I want to defend most directly, because it's counter-instinct.
The strong pull, when you're building a framework you'll need to defend up the chain, is to start with industry alignment. Pick the most recognised universal model. Map your work to it. Make it look credible first, so when the senior conversation happens you have the air cover of "we used the [Big Consultancy] standard."
Doing that first kills movement.
Industry-standard frameworks are calibrated to the median org. Your org isn't the median. If yours is smaller, more autonomous, more regulated, less central — the median framework will set the bar in places it shouldn't and miss the bar in places it should hit. Staff trying to use it get guided wrong on both ends. They spend cycles on the wrong things. Movement stalls. By the time you realise the framework isn't moving people, you're a year in and you've trained the org to associate "the AI framework" with "the slow, weird thing that doesn't help."
The sequence that's worked is the opposite:
- 2026 — tailored. Build the framework calibrated specifically to your org's constraints. Optimise for movement and guidance. Accept that it will not be externally benchmarkable yet. That's fine. The job in year one is to get things changing.
- 2027 — unified. Once movement is real and the org has built capability, evolve the framework toward a more structurally unified view that maps cleanly to the broader industry. Now you have something coherent to compare against the standards.
- 2028 — benchmarkable. Once unified, push for the external benchmarking, the certifiable governance overlay, the comparison against industry peers.
Movement first. Alignment second. Benchmarking third.
This sequencing requires trust — from the leadership chain, from the peer groups asking "why isn't this mapped to [universal model] yet?". You earn that trust by being explicit about the path. The "why this approach" page covers exactly this. Without it, the sequencing looks like avoidance. With it, it reads as deliberate strategy.
What I'd tell another transformation lead
If you're building a framework right now, the moves that actually mattered for me, in rough order:
- Define the three tests up front. Movement, guidance, measurement. Pin them on the wall. Every design decision goes through them.
- Run a real comparative assessment, not a citation list. For every contributing source, document what you kept, what you discarded, why. If you can't answer "why" for a source, don't cite it.
- Use a multi-model council for synthesis, not a single model. And stress-test the council's improvements against itself before adopting them. Plausible-sounding upgrades fail surprisingly often.
- Document every design decision with rationale, in the framework. The "why this approach" page isn't optional. It's the layer that lets the framework survive senior scrutiny.
- Separate structure from specifics. Stable structure, living specifics. Be explicit about which is which.
- Sequence movement before alignment before benchmarking. Resist the pull to make it look credible before it's productive.
None of those are clever. They're disciplines. The work is in holding them while the pressure to cut corners is real.
A few questions to ask before you ship it
If you're about to push a framework live, sit with these for ten minutes:
- What changes on Monday? If a team reads this on Friday, what do they actually do differently next week? If you can't name one specific behaviour, you have a description, not a framework.
- Where's the "why this approach" page? If a senior leader you've never met reads the framework and asks why these dimensions, why this sequencing, why these levels — does the framework answer them? Or does the answer live in your head?
- What did you discard, and why? Not what you kept — what you didn't keep. If every reference is a "yes," your synthesis isn't doing real work.
- What's the measurement signal? How will you know in six months whether this framework moved the org or just sat on a Confluence page? Be specific. "Adoption" isn't a signal. "BUs running their first self-assessment by Q3" is.
- What in this framework is structure, and what is specifics? If the underlying tech shifts in nine months, what stays and what updates? If you can't answer cleanly, the framework will go stale fast and people will stop trusting it.
If you've got good answers to all five, the framework is probably ready. If you don't, the work isn't in writing more — it's in answering the questions you don't have answers for yet.
The frameworks that move orgs aren't the ones that look the most rigorous. They're the ones built with enough discipline that the rigour is load-bearing. Most internal frameworks I've reviewed fail that test. The ones that don't tend to be quieter, more specific, more honest about their trade-offs — and they tend to actually move things.
That's the work worth doing.
This post is about the methodology of building a calibrated internal framework — not about the contents of any specific one. The worked example referenced throughout is an AI maturity model for a federation of small BUs, built through a multi-stage multi-model council across reputable industry sources.